2025年03月31日
C++の進化
結構前から、メインで使う言語は C++ になっているわけですが。
特にこだわりがあるわけではないんだけど、慣れると一番使いやすいというか、逆に Python のような動的な型付けにはなかなか馴染めなかったりします。ただ、最初の頃は手探り状態で、理由のわからない大量のエラーに悩まされたものです。特にテンプレートを使うとひどいものでしたね。
今でもエラーに悩まされることはあるし、どうやって構築するか長いこと考えさせられる時もあって、Python なんかは慣れるとたぶん楽なんだろうなと思うこともあります。で、本当に最近のことですけど、C++ がいろいろと進化していることを知って、もっと早く気づいていればと悔しい思いをしました。auto を使い始めたのはそれほど昔のことではないですし、decltype を知ったのは本当に最近のことです。パラメータパックも便利で、今ではあちこちで使うようになりました。
ずっとお世話になっていた cplusplus.com というサイト、実は内容が古くて、cppreference.com のほうに新しい仕様が記載されているので、今ではこちらをメインで使ってます。しかし、そろそろ Rust も本格的に勉強したいですね。
特にこだわりがあるわけではないんだけど、慣れると一番使いやすいというか、逆に Python のような動的な型付けにはなかなか馴染めなかったりします。ただ、最初の頃は手探り状態で、理由のわからない大量のエラーに悩まされたものです。特にテンプレートを使うとひどいものでしたね。
今でもエラーに悩まされることはあるし、どうやって構築するか長いこと考えさせられる時もあって、Python なんかは慣れるとたぶん楽なんだろうなと思うこともあります。で、本当に最近のことですけど、C++ がいろいろと進化していることを知って、もっと早く気づいていればと悔しい思いをしました。auto を使い始めたのはそれほど昔のことではないですし、decltype を知ったのは本当に最近のことです。パラメータパックも便利で、今ではあちこちで使うようになりました。
ずっとお世話になっていた cplusplus.com というサイト、実は内容が古くて、cppreference.com のほうに新しい仕様が記載されているので、今ではこちらをメインで使ってます。しかし、そろそろ Rust も本格的に勉強したいですね。
2024年10月06日
バグの嵐
先週のパフォーマンス問題は、あちらこちらに仕込んだエラー処理が原因でした。
無効化できるように対処したら、パフォーマンスがかなり改善しましたが、以前のプログラムよりまだ二倍くらい時間がかかるので、少し見直しを行ってようやく同等程度になりました。かなりプログラムは短くした気がするのに、同等程度というのはガッカリな結果ですけど、今度は GPU を使うようにさらなる改善を考えているので、今回はここまでとしています。
それより、根幹部分の計算処理にバグが見つかって、それが精度の低下を招いていました。我ながらつまらないミスをしたものだと思ってます。
とにかく、これでインセプションの動作試験ができる下準備が終わりました。これ以上、バグがないことを祈りつつ、作業を進めていきます。
無効化できるように対処したら、パフォーマンスがかなり改善しましたが、以前のプログラムよりまだ二倍くらい時間がかかるので、少し見直しを行ってようやく同等程度になりました。かなりプログラムは短くした気がするのに、同等程度というのはガッカリな結果ですけど、今度は GPU を使うようにさらなる改善を考えているので、今回はここまでとしています。
それより、根幹部分の計算処理にバグが見つかって、それが精度の低下を招いていました。我ながらつまらないミスをしたものだと思ってます。
とにかく、これでインセプションの動作試験ができる下準備が終わりました。これ以上、バグがないことを祈りつつ、作業を進めていきます。
2024年09月29日
パフォーマンスをよくするには?
パフォーマンスと言っても、作業効率ではなくて、プログラムの話です。
CNN の高速化をしてみたつもりが、逆に遅いという結果になりました。プロファイラで調べたところ、なぜか文字列操作の関数が大量に呼び出されているんですよね。デバッグ用に仕込んだ箇所の問題かと思い、無効にしてみたり、最終的にはコメントアウトしても結果が変わらず、結構困っています。
少なくとも、最初のバージョンより速く動いてほしいんだけど、今のところは遠く及ばない状態で、原因もわからない、というお手上げ状態で、これがうまくいけばインセプションの実験もできるんだけど、前に進めません。
今年中には決着をつけたいんだけど、どうなることやら。
CNN の高速化をしてみたつもりが、逆に遅いという結果になりました。プロファイラで調べたところ、なぜか文字列操作の関数が大量に呼び出されているんですよね。デバッグ用に仕込んだ箇所の問題かと思い、無効にしてみたり、最終的にはコメントアウトしても結果が変わらず、結構困っています。
少なくとも、最初のバージョンより速く動いてほしいんだけど、今のところは遠く及ばない状態で、原因もわからない、というお手上げ状態で、これがうまくいけばインセプションの実験もできるんだけど、前に進めません。
今年中には決着をつけたいんだけど、どうなることやら。
2024年08月06日
VAE
更新が遅くなってしまいました。
どうしても分からない問題があって、数週間悩んでいたのですが、ChatGPT に質問の内容を変えてみたらヒントが得られ、そこから解くことができました。いや、今の ChatGPT は本当に頼りになります。
さて、ストップしていたプログラム作成を再開し、インセプションの生成ももう少し頑張ればできそうな段階になってきました。できれば CUDA を使って GPU で処理とかさせてみたいけど、とりあえず今のやつを完成させたいです。
で、最近 VAE の勉強も始めて、コーディングそのものはそれほど難しくなさそうなので ( 理論は非常に難しいですけど )、こちらも作成を進めたいと考えています。
VAE、Variational Autoencoder の略ですね。名前から見てわかるように Autoencoder を利用しています。これが画像生成 AI などでも活用されているので、画像処理関連に利用してみたいと思ってます。
どうしても分からない問題があって、数週間悩んでいたのですが、ChatGPT に質問の内容を変えてみたらヒントが得られ、そこから解くことができました。いや、今の ChatGPT は本当に頼りになります。
さて、ストップしていたプログラム作成を再開し、インセプションの生成ももう少し頑張ればできそうな段階になってきました。できれば CUDA を使って GPU で処理とかさせてみたいけど、とりあえず今のやつを完成させたいです。
で、最近 VAE の勉強も始めて、コーディングそのものはそれほど難しくなさそうなので ( 理論は非常に難しいですけど )、こちらも作成を進めたいと考えています。
VAE、Variational Autoencoder の略ですね。名前から見てわかるように Autoencoder を利用しています。これが画像生成 AI などでも活用されているので、画像処理関連に利用してみたいと思ってます。
2024年03月25日
生成 AI
今頃かと言われそうですが、生成 AI やたらと流行っていますね。
ChatGPT から始まって、画像やら音楽やら、ついには動画まで生成できるようになったので、次は 3D モデルを生成する AI も登場するだろうと期待しています。
プログラムも、それなりのものが作れたりするので、技術の進歩には驚くばかりですが、さすがに無茶な要求に答えることはまだできませんでした。結構前の話になりますが、ChatGPT に Denoising Diffusion Probabilistic Models のサンプル・プログラムを書くように頼んだら、肝心のコアな部分はコメントで「ここにプログラムを書く」とだけ記述されていました。その部分を知りたいんですけどね。
プログラマーも不要になるのではと不安を煽るような記事もよく見かけますけど、まだ数年は大丈夫だろうと思っています。基本的に学習したこと以上のアイデアが浮かぶというような代物ではまだなさそうなので、例えば堅牢な OS を作れと命じても、今は不可能でしょうね。
当面は、もう少し基礎固めをしてから生成 AI にも挑んでいきたいです。まだ、RNN の検証で苦しんでいるところですが。
ChatGPT から始まって、画像やら音楽やら、ついには動画まで生成できるようになったので、次は 3D モデルを生成する AI も登場するだろうと期待しています。
プログラムも、それなりのものが作れたりするので、技術の進歩には驚くばかりですが、さすがに無茶な要求に答えることはまだできませんでした。結構前の話になりますが、ChatGPT に Denoising Diffusion Probabilistic Models のサンプル・プログラムを書くように頼んだら、肝心のコアな部分はコメントで「ここにプログラムを書く」とだけ記述されていました。その部分を知りたいんですけどね。
プログラマーも不要になるのではと不安を煽るような記事もよく見かけますけど、まだ数年は大丈夫だろうと思っています。基本的に学習したこと以上のアイデアが浮かぶというような代物ではまだなさそうなので、例えば堅牢な OS を作れと命じても、今は不可能でしょうね。
当面は、もう少し基礎固めをしてから生成 AI にも挑んでいきたいです。まだ、RNN の検証で苦しんでいるところですが。
2023年05月30日
CUDA (2)
梅雨に入ってしまいましたね。
CUDA を使った開発を Windows 上で行っているわけですけど、Linux とは環境が変わるので色々とトラブルもあったりします。どちらかといえば gcc を使ってコンパイルしたいですが、今のところは Microsoft の cl にしか対応していないということで、cl にしか出力されないエラーなんかに悩まされることが多いですね。CUDA 自体にもいろいろと制約があるので、対応方法が見つからず、しばらく開発がストップすることもしばしば。
ようやく、ニューラルネットワークを CUDA で処理できるようプログラムは完成し、動作テストしてみたけど一発では動かないですねえ。いろいろと苦戦中の状態です。
CUDA を使った開発を Windows 上で行っているわけですけど、Linux とは環境が変わるので色々とトラブルもあったりします。どちらかといえば gcc を使ってコンパイルしたいですが、今のところは Microsoft の cl にしか対応していないということで、cl にしか出力されないエラーなんかに悩まされることが多いですね。CUDA 自体にもいろいろと制約があるので、対応方法が見つからず、しばらく開発がストップすることもしばしば。
ようやく、ニューラルネットワークを CUDA で処理できるようプログラムは完成し、動作テストしてみたけど一発では動かないですねえ。いろいろと苦戦中の状態です。
2023年05月15日
ChatGPTの使い所は?
使い始めると便利な ChatGPT ですが、万能というわけではありません。
プログラム関係には強いというのが一般的な評価になっていると思うんですけど、ちょっと厄介な問題を尋ねると変な答えが返ってくることがあります。C++ でのムーブセマンティックという、今まで使ったことがなかった仕組みを今回使う必要が生じて、派生クラスなどの絡みもあり、これで正しいコードであるのかと聞いてみたところ、問題があると回答が得られ、修正案も提示されました。ところが、その修正案がどう考えても間違いで、ここがおかしいと指摘したら謝罪とともにソースコードを修正して再出力します。それを何度やっても、正しい答えになはらず、最後には元のコードに逆戻りしました。それを見た時は、笑いましたね。
的確に答えを出してくれることもありますが、感覚としては半々の正解率といった感じで、正解になっていそうなコードも注意深くチェックしないと結局使えなかったりと、まだ改善の余地があるようです。
でもGoogleで検索して調べることを考えたら、ヒントを与えてくれるツールとして捉えれば非常に便利なものです。プログラマの人なんかは活用すると非常に重宝すると思いますよ。
プログラム関係には強いというのが一般的な評価になっていると思うんですけど、ちょっと厄介な問題を尋ねると変な答えが返ってくることがあります。C++ でのムーブセマンティックという、今まで使ったことがなかった仕組みを今回使う必要が生じて、派生クラスなどの絡みもあり、これで正しいコードであるのかと聞いてみたところ、問題があると回答が得られ、修正案も提示されました。ところが、その修正案がどう考えても間違いで、ここがおかしいと指摘したら謝罪とともにソースコードを修正して再出力します。それを何度やっても、正しい答えになはらず、最後には元のコードに逆戻りしました。それを見た時は、笑いましたね。
的確に答えを出してくれることもありますが、感覚としては半々の正解率といった感じで、正解になっていそうなコードも注意深くチェックしないと結局使えなかったりと、まだ改善の余地があるようです。
でもGoogleで検索して調べることを考えたら、ヒントを与えてくれるツールとして捉えれば非常に便利なものです。プログラマの人なんかは活用すると非常に重宝すると思いますよ。
2021年05月09日
Visual Studio Code
今まで、ソースコードや HTML の編集には Emacs をメインで使っていました。
しかし、あの独特のコマンド入力があまり好きではなく、IDE のように自動補完などの便利な機能もないので ( 自動インデントなどは重宝しますけどね )、以前から代わりとなるエディタを探していました。
Atom の人気が高いということで使ってみたけど、日本語入力に難ありということで、Windows 上では gPad というフリーソフトに落ち着いています。そして Linux 上でもついに代替品を見つけました。Microsoft の提供している Visual Studio Code です。
自動補完はもちろんのこと、エラー箇所の検出や関数のコメント表示など、IDE にある便利な機能はほぼ揃っています。もう、Emacs に戻ることはできませんね。
今のところ、Emacs も残してはいますが、そのうちバッサリと削除するかも知れません。長い間、慣れ親しんだエディタではあるので、ちょっと名残惜しい気もしますけどね。
しかし、あの独特のコマンド入力があまり好きではなく、IDE のように自動補完などの便利な機能もないので ( 自動インデントなどは重宝しますけどね )、以前から代わりとなるエディタを探していました。
Atom の人気が高いということで使ってみたけど、日本語入力に難ありということで、Windows 上では gPad というフリーソフトに落ち着いています。そして Linux 上でもついに代替品を見つけました。Microsoft の提供している Visual Studio Code です。
自動補完はもちろんのこと、エラー箇所の検出や関数のコメント表示など、IDE にある便利な機能はほぼ揃っています。もう、Emacs に戻ることはできませんね。
今のところ、Emacs も残してはいますが、そのうちバッサリと削除するかも知れません。長い間、慣れ親しんだエディタではあるので、ちょっと名残惜しい気もしますけどね。
2021年03月21日
Rust
大雨の日は憂鬱になりますね。しかし、明日は晴れそうです。
最近、Rust という言語があるのを発見しました。昔から知っている方にとっては何をいまさらと言われそうですが、最近になって特に注目されている言語のようですね。
C や C++ に比べて安全、しかも高速に動作する反面、習得するのは難しいそうです。少しずつですが、勉強を始めようとしているところです。
マスターしたら、今まで作成したライブラリを Rust に置き換えるようなこともしてみたいですね。
最近、Rust という言語があるのを発見しました。昔から知っている方にとっては何をいまさらと言われそうですが、最近になって特に注目されている言語のようですね。
C や C++ に比べて安全、しかも高速に動作する反面、習得するのは難しいそうです。少しずつですが、勉強を始めようとしているところです。
マスターしたら、今まで作成したライブラリを Rust に置き換えるようなこともしてみたいですね。
2019年04月14日
クラス・テンプレートのコピー・コンストラクタについて
今日は昼から雨が降り始めました。明日も雨のようです。桜もだいぶ散ってしまいそうです。
散歩の途中で撮影した桜です。毎年、同じような写真をアップロードしているような気がします。

今回はプログラミングの話題です。以下のようなクラス・テンプレートを作成したとします。
template< class T >
class Test
{
public:
Test( T t )
{ cout << "Test( T t ) called" << endl; }
template< class U >
Test( const Test< U >& t )
{ cout << "Test( const Test< U >& t ) called" << endl; }
template< class U >
Test& operator=( const Test< U >& t )
{ cout << "Test& operator=( const Test< U >& t ) called" << endl; return( *this ); }
};
次のように使ってみます。
Test< double > testDbl( 1 );
Test< int > testIntCopy( testDbl );
Test< double > testDblCopy( testDbl );
testIntCopy = testDbl;
testDblCopy = testDbl;
今まで、テンプレートを使った任意の型への変換用コンストラクタから、同じ型へのコピー・コンストラクタが作成されるものと思っていました。しかし、実行結果は
Test( T t ) called
Test( const Test< U >& t ) called
Test& operator=( const Test< U >& t ) called
となって、同じ型へのコピー・コンストラクタはコンパイラが自動的に作成したものが使われます。ちゃんと明示したければ、
Test( const Test& t )
{ cout << "Test( const Test& t ) called" << endl; }
Test& operator=( const Test& t )
{ cout << "Test& operator=( const Test& t ) called" << endl; return( *this ); }
という感じに定義してあげないとダメでした。これらを追加すると
Test( T t ) called
Test( const Test< U >& t ) called
Test( const Test& t ) called
Test& operator=( const Test< U >& t ) called
Test& operator=( const Test& t ) called
という風に出力されます。以前作ったプログラムで同じ誤りがあって、よく今まで問題が発生しなかったものだと少し焦りました。その後、「プログラム言語 C++」を見たらちゃんと書いてありました。
散歩の途中で撮影した桜です。毎年、同じような写真をアップロードしているような気がします。
今回はプログラミングの話題です。以下のようなクラス・テンプレートを作成したとします。
template< class T >
class Test
{
public:
Test( T t )
{ cout << "Test( T t ) called" << endl; }
template< class U >
Test( const Test< U >& t )
{ cout << "Test( const Test< U >& t ) called" << endl; }
template< class U >
Test& operator=( const Test< U >& t )
{ cout << "Test& operator=( const Test< U >& t ) called" << endl; return( *this ); }
};
次のように使ってみます。
Test< double > testDbl( 1 );
Test< int > testIntCopy( testDbl );
Test< double > testDblCopy( testDbl );
testIntCopy = testDbl;
testDblCopy = testDbl;
今まで、テンプレートを使った任意の型への変換用コンストラクタから、同じ型へのコピー・コンストラクタが作成されるものと思っていました。しかし、実行結果は
Test( T t ) called
Test( const Test< U >& t ) called
Test& operator=( const Test< U >& t ) called
となって、同じ型へのコピー・コンストラクタはコンパイラが自動的に作成したものが使われます。ちゃんと明示したければ、
Test( const Test& t )
{ cout << "Test( const Test& t ) called" << endl; }
Test& operator=( const Test& t )
{ cout << "Test& operator=( const Test& t ) called" << endl; return( *this ); }
という感じに定義してあげないとダメでした。これらを追加すると
Test( T t ) called
Test( const Test< U >& t ) called
Test( const Test& t ) called
Test& operator=( const Test< U >& t ) called
Test& operator=( const Test& t ) called
という風に出力されます。以前作ったプログラムで同じ誤りがあって、よく今まで問題が発生しなかったものだと少し焦りました。その後、「プログラム言語 C++」を見たらちゃんと書いてありました。
2019年01月27日
大坂なおみ
全豪オープンで大坂なおみ選手が見事優勝を果たし、テレビや新聞で大々的に取り上げられてました。
そんな中で、男子の方はジョコビッチが優勝。これも何気にすごいと思います。
-----
C++ でおなじみのテンプレートですが、テンプレート引数にもテンプレートを使うことができます。例えばこんな感じです。
template< class T, template< class > class Op >
SomeClass
{
Op< T > op_;
:
};
テンプレート引数を付けないと SomeClass< double, SomeOp< double > > と書かなければならないのが、上記のようにすることで SomeClass< double, SomeOp > だけで済むようになります。誤って SomeOp< int > と書いてしまうようなミスも防げるというわけです。但し、利用できるのはクラステンプレートのみです。
意外と知られていないように思うので紹介しておきます。「プログラミング言語 C++」にも書かれていますが、自分は別の書籍で知りました。
そんな中で、男子の方はジョコビッチが優勝。これも何気にすごいと思います。
-----
C++ でおなじみのテンプレートですが、テンプレート引数にもテンプレートを使うことができます。例えばこんな感じです。
template< class T, template< class > class Op >
SomeClass
{
Op< T > op_;
:
};
テンプレート引数を付けないと SomeClass< double, SomeOp< double > > と書かなければならないのが、上記のようにすることで SomeClass< double, SomeOp > だけで済むようになります。誤って SomeOp< int > と書いてしまうようなミスも防げるというわけです。但し、利用できるのはクラステンプレートのみです。
意外と知られていないように思うので紹介しておきます。「プログラミング言語 C++」にも書かれていますが、自分は別の書籍で知りました。
2016年10月30日
自己組織化写像(SOM)
めっきり寒くなってきました。今年も残り二ヶ月ですね。
クラスタリングの一つ、SOM ( Self-organizing maps ) のサンプル・プログラムを作成してみました。SOM を使うことで、高次元のデータを二次元マップ上に写像して視覚的に分類することが可能になります。
紹介しているサイトを見ると、理解しやすい色のクラスタリングが例としてよく挙がっていますが、巡回サラリーマン問題の近似解を求める応用例を見つけてさっそく試してみました。二次元データを二次元マップに写像することで目的を達成することができます。
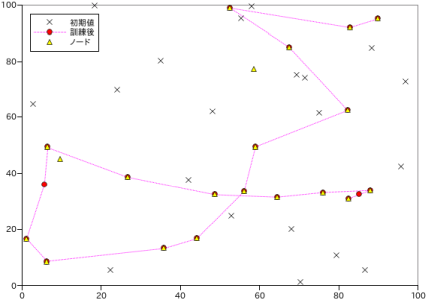
初期値 "×" を与えて訓練すると、"△" のノードに次第に近づいていきます。真の解ではないですが、割りといい結果が得られているのではないかと思います。この使い方を見つけてから SOM を使うのがなかなか面白くなってきました。
クラスタリングには他にも凝集型クラスタリングや K-平均法、EM アルゴリズムなどがありますが、現在、順番にサンプル・プログラムを作成しようとしているところです。年内にできれば一度更新したいですね。
クラスタリングの一つ、SOM ( Self-organizing maps ) のサンプル・プログラムを作成してみました。SOM を使うことで、高次元のデータを二次元マップ上に写像して視覚的に分類することが可能になります。
紹介しているサイトを見ると、理解しやすい色のクラスタリングが例としてよく挙がっていますが、巡回サラリーマン問題の近似解を求める応用例を見つけてさっそく試してみました。二次元データを二次元マップに写像することで目的を達成することができます。
初期値 "×" を与えて訓練すると、"△" のノードに次第に近づいていきます。真の解ではないですが、割りといい結果が得られているのではないかと思います。この使い方を見つけてから SOM を使うのがなかなか面白くなってきました。
クラスタリングには他にも凝集型クラスタリングや K-平均法、EM アルゴリズムなどがありますが、現在、順番にサンプル・プログラムを作成しようとしているところです。年内にできれば一度更新したいですね。
2016年06月26日
演算子の多重定義
今日はそれほど暑くもなく、カラッとしたいい天気でした。しかし、明日からまた雨のようですね。
C++ には「演算子の多重定義」というものがあります。任意の型に対して、int 型や double 型などと同等に演算子が利用できるというものです。
SomeClass SomeClass::operator+( const SomeClass& s1, const SomeClass& s2 );
という関数を実装すれば、
SomeClass s1, s2;
:
// 何らかの方法で値を代入
:
SomeClass add = s1 + s2;
と書くことができます。四則演算だけではなく、等号・不等号演算子やポインタ・参照演算子なども多重定義できるので、うまく利用すれば非常に便利な反面、やみくもに使うと混乱の元とも言われています。例えば、ベクトルに対して積の演算子を多重定義した場合、それは内積なのか外積なのかというのは利用する場面によって変わります。こんなときは素直に innerproduct, outerproduct と通常の関数を用意したほうが混乱しなくて済みます。
演算子の多重定義の実体は関数やメンバ関数です。そうなると、演算子の優先順位はどうなるのかが気になるところです。簡単なサンプルを作ってテストしてみました。
/// 10 を法とした合同算
struct Mod10
{
unsigned int r; // 10 を法としたときの値
// コンストラクタ
Mod10() : r( 0 ) {}
// 積の代入演算子の多重定義
Mod10& operator*=( const Mod10& i )
{
r = ( r * i.r ) % 10;
return( *this );
}
// 和の代入演算子の多重定義
Mod10& operator+=( const Mod10& i )
{
r = ( r + i.r ) % 10;
return( *this );
}
};
// 積の演算子の多重定義
Mod10 operator*( const Mod10& i1, const Mod10& i2 )
{
Mod10 buff( i1 );
buff *= i2;
return( buff );
}
// 和の演算子の多重定義
Mod10 operator+( const Mod10& i1, const Mod10& i2 )
{
Mod10 buff( i1 );
buff += i2;
return( buff );
}
int main( int argc, char* argv[] )
{
if ( argc < 3 ) return( -1 );
unsigned int i = atoi( argv[1] );
unsigned int j = atoi( argv[2] );
Mod10 m1; m1.r = i;
Mod10 m2; m2.r = j;
Mod10 ans1 = m2 * m1 + m1;
Mod10 ans2 = m1 + m1 * m2;
Mod10 ans3 = ( m1 + m1 ) * m2;
std::cout << ans1.r << std::endl;
std::cout << ans2.r << std::endl;
std::cout << ans3.r << std::endl;
}
演算子の優先順位を考慮していなければ、関数に置き換えると
Mod10 ans1 = operator*( m2, operator+( m1, m1 ) );
Mod10 ans2 = operator+( m1, operator*( m1, m2 ) );
か
Mod10 ans1 = operator+( operator*( m2, m1 ), m1 );
Mod10 ans2 = operator*( operator+( m1, m1 ), m2 );
となって、ans1 と ans2 の値は異なるのではないかと予想していましたが、例えば m1 = 2, m2 = 3 とすると、
8
8
2
となってちゃんと優先順位が考慮されていました。で、「プログラミング言語 C++」を調べてみたら、最初の方に「優先順位を考慮している」ときちんと記述されていました。それにしても、今まで何回か使ったことがあるのに疑問に思わなかったというのが少々情けない。。。
C++ には「演算子の多重定義」というものがあります。任意の型に対して、int 型や double 型などと同等に演算子が利用できるというものです。
SomeClass SomeClass::operator+( const SomeClass& s1, const SomeClass& s2 );
という関数を実装すれば、
SomeClass s1, s2;
:
// 何らかの方法で値を代入
:
SomeClass add = s1 + s2;
と書くことができます。四則演算だけではなく、等号・不等号演算子やポインタ・参照演算子なども多重定義できるので、うまく利用すれば非常に便利な反面、やみくもに使うと混乱の元とも言われています。例えば、ベクトルに対して積の演算子を多重定義した場合、それは内積なのか外積なのかというのは利用する場面によって変わります。こんなときは素直に innerproduct, outerproduct と通常の関数を用意したほうが混乱しなくて済みます。
演算子の多重定義の実体は関数やメンバ関数です。そうなると、演算子の優先順位はどうなるのかが気になるところです。簡単なサンプルを作ってテストしてみました。
/// 10 を法とした合同算
struct Mod10
{
unsigned int r; // 10 を法としたときの値
// コンストラクタ
Mod10() : r( 0 ) {}
// 積の代入演算子の多重定義
Mod10& operator*=( const Mod10& i )
{
r = ( r * i.r ) % 10;
return( *this );
}
// 和の代入演算子の多重定義
Mod10& operator+=( const Mod10& i )
{
r = ( r + i.r ) % 10;
return( *this );
}
};
// 積の演算子の多重定義
Mod10 operator*( const Mod10& i1, const Mod10& i2 )
{
Mod10 buff( i1 );
buff *= i2;
return( buff );
}
// 和の演算子の多重定義
Mod10 operator+( const Mod10& i1, const Mod10& i2 )
{
Mod10 buff( i1 );
buff += i2;
return( buff );
}
int main( int argc, char* argv[] )
{
if ( argc < 3 ) return( -1 );
unsigned int i = atoi( argv[1] );
unsigned int j = atoi( argv[2] );
Mod10 m1; m1.r = i;
Mod10 m2; m2.r = j;
Mod10 ans1 = m2 * m1 + m1;
Mod10 ans2 = m1 + m1 * m2;
Mod10 ans3 = ( m1 + m1 ) * m2;
std::cout << ans1.r << std::endl;
std::cout << ans2.r << std::endl;
std::cout << ans3.r << std::endl;
}
演算子の優先順位を考慮していなければ、関数に置き換えると
Mod10 ans1 = operator*( m2, operator+( m1, m1 ) );
Mod10 ans2 = operator+( m1, operator*( m1, m2 ) );
か
Mod10 ans1 = operator+( operator*( m2, m1 ), m1 );
Mod10 ans2 = operator*( operator+( m1, m1 ), m2 );
となって、ans1 と ans2 の値は異なるのではないかと予想していましたが、例えば m1 = 2, m2 = 3 とすると、
8
8
2
となってちゃんと優先順位が考慮されていました。で、「プログラミング言語 C++」を調べてみたら、最初の方に「優先順位を考慮している」ときちんと記述されていました。それにしても、今まで何回か使ったことがあるのに疑問に思わなかったというのが少々情けない。。。
2015年11月01日
コンストラクタと例外
エラー処理の話の続きです。
C++ での例外処理でよく話題になるのが「コンストラクタで例外を使ってよいか」という件。今ではガンガン使うようにしています。
コンストラクタは戻り値が得られないので、インスタンス化に失敗したかどうかを知るためには、成否を判断するためのフラグをメンバ変数として設けておいて実際に利用する前に判断させるというのがよく使われる方法です。以前は例外の使用は極力避けるようにしていたのでこの方法を採用していましたが、コンストラクタ内で利用する関数が例外を投げた場合を想定してきちんと捕捉して処理しなければならずコーディングが面倒になるし、単にフラグだけでは内部で何が起こったのかわからないので呼び出し側から見ても使いづらいところはあります ( メッセージ出力したり、エラー・コードを管理する手もありますがますますコーディングが大変になってきます) 。なので、今では逆に例外を多用するようにしています。
コンストラクタでの例外を禁止する理由は一般に「メモリ・リーク」の原因になるというものですが、内部で例外が発生したのならそれを捕捉して後処理をしてから再スローすれば済みます。あるサイトで見かけたのがこういうタイプのもの。
SomeClass* p = 0;
try
{
:
p = new SomeClass();
:
}
cacth (...)
{
(後処理)
}
delete p;
コンストラクタ内で例外が発生したら、p にアドレスが代入される前に catch 節に写ってしまうので、最後の delete p でもオブジェクトは解体されず、メモリ・リークになってしまうように見えます。しかし、ここはちゃんと対策されていて、コンストラクタで例外が投げられたら自動的に delete がよばれ、SomeClass 用に確保されたメモリはきちんと開放されます。但し、SomeClass のデストラクタは呼び出されないので、コンストラクタ内で new を使っている場合は例外を捕捉して後処理を行うことは必須となります。
クラス内で使うメンバのサイズが大きくなければ、new を使って動的にメモリ確保しない方がソースはすっきりしますが、そういうわけにもいかないですよね。
C++ での例外処理でよく話題になるのが「コンストラクタで例外を使ってよいか」という件。今ではガンガン使うようにしています。
コンストラクタは戻り値が得られないので、インスタンス化に失敗したかどうかを知るためには、成否を判断するためのフラグをメンバ変数として設けておいて実際に利用する前に判断させるというのがよく使われる方法です。以前は例外の使用は極力避けるようにしていたのでこの方法を採用していましたが、コンストラクタ内で利用する関数が例外を投げた場合を想定してきちんと捕捉して処理しなければならずコーディングが面倒になるし、単にフラグだけでは内部で何が起こったのかわからないので呼び出し側から見ても使いづらいところはあります ( メッセージ出力したり、エラー・コードを管理する手もありますがますますコーディングが大変になってきます) 。なので、今では逆に例外を多用するようにしています。
コンストラクタでの例外を禁止する理由は一般に「メモリ・リーク」の原因になるというものですが、内部で例外が発生したのならそれを捕捉して後処理をしてから再スローすれば済みます。あるサイトで見かけたのがこういうタイプのもの。
SomeClass* p = 0;
try
{
:
p = new SomeClass();
:
}
cacth (...)
{
(後処理)
}
delete p;
コンストラクタ内で例外が発生したら、p にアドレスが代入される前に catch 節に写ってしまうので、最後の delete p でもオブジェクトは解体されず、メモリ・リークになってしまうように見えます。しかし、ここはちゃんと対策されていて、コンストラクタで例外が投げられたら自動的に delete がよばれ、SomeClass 用に確保されたメモリはきちんと開放されます。但し、SomeClass のデストラクタは呼び出されないので、コンストラクタ内で new を使っている場合は例外を捕捉して後処理を行うことは必須となります。
クラス内で使うメンバのサイズが大きくなければ、new を使って動的にメモリ確保しない方がソースはすっきりしますが、そういうわけにもいかないですよね。
2015年10月25日
エラー処理
趣味であれ仕事であれ、プログラム作成で一番頭を悩ませるのはエラー処理だと思っています。
何か新しいアルゴリズムを考案したり理解したりしてプログラムを作成するというのは、少なくとも日曜プログラミングなんかをやっている方なら非常に楽しい作業なのではないかと思います。しかし、不測の事態が起きた場合や、意図しない入力があった場合に備えてきちんとしたエラー処理を組み込もうとした途端に楽しかったはずの作業が苦痛に変わります。個人的には、デバッグ同様できるだけ避けたい作業の一つで、退屈なだけにエラー処理を考える方が苦痛に感じます。
エラー処理は、プログラムも冗長にしがちです。それを避けるために「例外処理」という機構が C++ や Java、C# などでは用意されています。例外を上手に使えば、プログラムを非常にシンプルにすることができます。しかし、C 言語などで組んでいるために既存のプログラムが例外を全く使っていない場合、そのプログラムは全て見直しが必要になるので、google のスタイルガイドでは「C++ で例外は使ってはいけない」としています。
例外処理を利用しない場合、外部から利用するための関数を作成した時に外部にエラーを通知するためには
1) エラーコードを戻り値として渡す
2) エラーメッセージを画面に出力する
3) 何もせずに戻る
くらいの方法が考えられます。
戻り値にエラーコードを返す場合、戻り値は通常、他の用途に使えなくなるので、何らかの値を得たい場合は引数を通して得る必要があります。また、エラーコード自体もきちんと管理しなければなりません。それから、エラーメッセージを出力しても、それがプログラム側に伝わるわけではなく、これだけで充分ということはまずないでしょう。何もしないというのは、外部にエラーが発生したことが検知できないことを意味しますが、結果からそれを知ることができれば充分ということも場合によってはあります。たいていは、エラーコードとエラーメッセージの組み合わせを利用しますが、それを呼び出し元がきちんと見てくれるかという問題もあり、関数が出力するエラー全てに対して一つ一つきちんと対応するコードを書いていたらキリがなく、どこかで妥協することが多くなります。
例外処理を利用すると、例外は呼び出し元に次々と伝播していきます。通常のアプリなら、メイン・ルーチンのところだけで例外を捕捉して、メッセージを出力して終了としておくだけでも十分な場合が多く、それなら途中の関数などで例外の補足時に行わなければならないことを必要最低限な部分だけ書いておけば、エラー処理部分はかなり簡潔にまとめることができます。
ということで、特に Java や C# であれば、エラー処理は基本的に例外を使うことになるし、C++ だけでコーディングするのなら迷わず例外を使うべきでしょうね。
何か新しいアルゴリズムを考案したり理解したりしてプログラムを作成するというのは、少なくとも日曜プログラミングなんかをやっている方なら非常に楽しい作業なのではないかと思います。しかし、不測の事態が起きた場合や、意図しない入力があった場合に備えてきちんとしたエラー処理を組み込もうとした途端に楽しかったはずの作業が苦痛に変わります。個人的には、デバッグ同様できるだけ避けたい作業の一つで、退屈なだけにエラー処理を考える方が苦痛に感じます。
エラー処理は、プログラムも冗長にしがちです。それを避けるために「例外処理」という機構が C++ や Java、C# などでは用意されています。例外を上手に使えば、プログラムを非常にシンプルにすることができます。しかし、C 言語などで組んでいるために既存のプログラムが例外を全く使っていない場合、そのプログラムは全て見直しが必要になるので、google のスタイルガイドでは「C++ で例外は使ってはいけない」としています。
例外処理を利用しない場合、外部から利用するための関数を作成した時に外部にエラーを通知するためには
1) エラーコードを戻り値として渡す
2) エラーメッセージを画面に出力する
3) 何もせずに戻る
くらいの方法が考えられます。
戻り値にエラーコードを返す場合、戻り値は通常、他の用途に使えなくなるので、何らかの値を得たい場合は引数を通して得る必要があります。また、エラーコード自体もきちんと管理しなければなりません。それから、エラーメッセージを出力しても、それがプログラム側に伝わるわけではなく、これだけで充分ということはまずないでしょう。何もしないというのは、外部にエラーが発生したことが検知できないことを意味しますが、結果からそれを知ることができれば充分ということも場合によってはあります。たいていは、エラーコードとエラーメッセージの組み合わせを利用しますが、それを呼び出し元がきちんと見てくれるかという問題もあり、関数が出力するエラー全てに対して一つ一つきちんと対応するコードを書いていたらキリがなく、どこかで妥協することが多くなります。
例外処理を利用すると、例外は呼び出し元に次々と伝播していきます。通常のアプリなら、メイン・ルーチンのところだけで例外を捕捉して、メッセージを出力して終了としておくだけでも十分な場合が多く、それなら途中の関数などで例外の補足時に行わなければならないことを必要最低限な部分だけ書いておけば、エラー処理部分はかなり簡潔にまとめることができます。
ということで、特に Java や C# であれば、エラー処理は基本的に例外を使うことになるし、C++ だけでコーディングするのなら迷わず例外を使うべきでしょうね。
2015年10月11日
ポインタの呪い
明日は体育の日で休みですね。
C言語を使う上で避けることのできない(使わなくてもなんとかなるかもしれませんが)概念に「ポインタ」があります。
int i = 3;
int* ip = &i;
と書くと、ip は i へのポインタ ( i を指し示すもの ) となって、
int j = *ip;
と書けば j に ip が指し示す i の値が代入され、
*ip = 6;
と書けば ip が指し示す i に 6 が代入されます。
理解すれば非常に便利なポインタですが、これのせいで C 言語のマスターをあきらめたという人も多いようです。たいていは、変数がメモリ上に保持される様子を使って説明されていたりして、特に初心者にとってはわかりづらいのではないのでしょうか。また、文法そのものもとっつきにくい原因となっていると思います。関数からポインタそのものを受け取りたいような場合は
void f( size_t sz, char** cpp )
{
*cpp = malloc( sz );
}
という具合に '**' で「ポインタのポインタ(ハンドル)」を表します。さらに関数ポインタの配列などは型の書き方がややこしくてたいていは忘れてしまい、本を見て思い出すといった具合です。C++ では参照が使えるようになって、ポインタはあまり意識しなくてもいいようになりました。関数ポインタも、関数オブジェクトというさらに便利な機能によってほとんど利用せずに済みます。
さらに Java や C# は「オブジェクトは参照渡しで組み込み変数は値渡し」と決められているので、完全にポインタのようなややこしい部分は意識しなくてよくなったわけですが、「参照渡しだから」ということで関数内で新しいインスタンスを構築して渡そうとしてうまくいかないといった失敗例をよく見かけます。
void f( SomeClass sc )
{
sc = new sc( ... );
}
この場合、C 言語でいうところの "普通の" ポインタ渡しを意味するので、オブジェクトのある位置が変数として渡されるだけです。その変数に新たなインスタンスの位置を代入しても、元のインスタンスは影響を受けないので意味がないわけです。ちなみに C# の場合はハンドルを渡すために ref キーワードがありますね。
void f( ref SomeClass sc )
{
sc = new sc( ... );
}
とすれば、意図したとおり新たなインスタンスで書き換えてくれます。
もし、このあたりで悩んでいる方がいれば、参考になれば幸いです。
C言語を使う上で避けることのできない(使わなくてもなんとかなるかもしれませんが)概念に「ポインタ」があります。
int i = 3;
int* ip = &i;
と書くと、ip は i へのポインタ ( i を指し示すもの ) となって、
int j = *ip;
と書けば j に ip が指し示す i の値が代入され、
*ip = 6;
と書けば ip が指し示す i に 6 が代入されます。
理解すれば非常に便利なポインタですが、これのせいで C 言語のマスターをあきらめたという人も多いようです。たいていは、変数がメモリ上に保持される様子を使って説明されていたりして、特に初心者にとってはわかりづらいのではないのでしょうか。また、文法そのものもとっつきにくい原因となっていると思います。関数からポインタそのものを受け取りたいような場合は
void f( size_t sz, char** cpp )
{
*cpp = malloc( sz );
}
という具合に '**' で「ポインタのポインタ(ハンドル)」を表します。さらに関数ポインタの配列などは型の書き方がややこしくてたいていは忘れてしまい、本を見て思い出すといった具合です。C++ では参照が使えるようになって、ポインタはあまり意識しなくてもいいようになりました。関数ポインタも、関数オブジェクトというさらに便利な機能によってほとんど利用せずに済みます。
さらに Java や C# は「オブジェクトは参照渡しで組み込み変数は値渡し」と決められているので、完全にポインタのようなややこしい部分は意識しなくてよくなったわけですが、「参照渡しだから」ということで関数内で新しいインスタンスを構築して渡そうとしてうまくいかないといった失敗例をよく見かけます。
void f( SomeClass sc )
{
sc = new sc( ... );
}
この場合、C 言語でいうところの "普通の" ポインタ渡しを意味するので、オブジェクトのある位置が変数として渡されるだけです。その変数に新たなインスタンスの位置を代入しても、元のインスタンスは影響を受けないので意味がないわけです。ちなみに C# の場合はハンドルを渡すために ref キーワードがありますね。
void f( ref SomeClass sc )
{
sc = new sc( ... );
}
とすれば、意図したとおり新たなインスタンスで書き換えてくれます。
もし、このあたりで悩んでいる方がいれば、参考になれば幸いです。
2015年09月12日
プログラミングの勧め
大雨が過ぎたら今度は地震。どうやら明日も雨になりそうですね。
仕事で作業をもっと短時間でできるようにシステム化できないかと相談があり、打ち合わせした時の話です。処理条件変更後のパラメータの変化を確認するためグラフで一枚一枚出力しながら目視確認していて、パラメータも処理のステップも大量にあるので全て見切れないということで、グラフを一度に全て出力できないかというのが要望だったわけですが、大量のグラフをまとめて書かせようとすると結構大変なのでどうやって処理させようかと話していたとき、ふと、グラフのプロットが二点しかないのを見て「どの程度のプロット数になるのですか」と質問すると、「1, 2 点です」との回答。じゃあ、表形式にしてスペックアウトしたら色付けすればということであっさりと解決しました。
なぜわざわざグラフを使っていたかというと、それしか手段を知らなかったからということで、本当はデータを取得するツールはあるので工夫すればいくらでも効率よく作業できるようになるわけですが、そういうところは苦手なのかなと感じました。今はそれぞれの分野が専業的になって、データ加工などの仕組みはいわゆる IT 分野の仕事となっています。でも、簡単なものなら自前で作成できたほうが何かといいんじゃないかなと思ってます。IT 担当の数も限られていますしね。
プログラムの世界も敷居が低くなったと言われますが、本当の初心者にとっては昔より逆に高くなっているのかもしれません。オブジェクト指向にシフトして大きなプログラムは組みやすくなりました。でも、ちょっとしたものなら C 言語のような手続き型言語でも十分というよりかえって効率はいいような気がします。自分が最初に作ったプログラムは、PC-88 上の BASIC で書いた「ブロックくずし」でした。本に書いてあったものをまずは読みながら組み上げて、後でいろいろと変更して遊んだりしてました。こういう学習の仕方は本当に効果的だと感じました。ちょっと使い方がわかれば、プログラミングは仕事でもプライベートでも非常に強力な味方になってくれるはずなので、参考にしてもらえればと思います。
仕事で作業をもっと短時間でできるようにシステム化できないかと相談があり、打ち合わせした時の話です。処理条件変更後のパラメータの変化を確認するためグラフで一枚一枚出力しながら目視確認していて、パラメータも処理のステップも大量にあるので全て見切れないということで、グラフを一度に全て出力できないかというのが要望だったわけですが、大量のグラフをまとめて書かせようとすると結構大変なのでどうやって処理させようかと話していたとき、ふと、グラフのプロットが二点しかないのを見て「どの程度のプロット数になるのですか」と質問すると、「1, 2 点です」との回答。じゃあ、表形式にしてスペックアウトしたら色付けすればということであっさりと解決しました。
なぜわざわざグラフを使っていたかというと、それしか手段を知らなかったからということで、本当はデータを取得するツールはあるので工夫すればいくらでも効率よく作業できるようになるわけですが、そういうところは苦手なのかなと感じました。今はそれぞれの分野が専業的になって、データ加工などの仕組みはいわゆる IT 分野の仕事となっています。でも、簡単なものなら自前で作成できたほうが何かといいんじゃないかなと思ってます。IT 担当の数も限られていますしね。
プログラムの世界も敷居が低くなったと言われますが、本当の初心者にとっては昔より逆に高くなっているのかもしれません。オブジェクト指向にシフトして大きなプログラムは組みやすくなりました。でも、ちょっとしたものなら C 言語のような手続き型言語でも十分というよりかえって効率はいいような気がします。自分が最初に作ったプログラムは、PC-88 上の BASIC で書いた「ブロックくずし」でした。本に書いてあったものをまずは読みながら組み上げて、後でいろいろと変更して遊んだりしてました。こういう学習の仕方は本当に効果的だと感じました。ちょっと使い方がわかれば、プログラミングは仕事でもプライベートでも非常に強力な味方になってくれるはずなので、参考にしてもらえればと思います。
2015年08月30日
暑さが思考を鈍らせる
大雨の日が続きますね。しかし、おかげで涼しくなってきました。
最近になって思うのは、温度より湿度のほうが「暑苦しい」という感覚に影響しているということです。30 度を超えていても湿度の低い日は案外エアコンなしで大丈夫だったりしました。逆に 30 度以下でも湿度が高いときは耐えられないですね。だいたい 60% くらいがリミットでしょうか。
暑いと思考回路も鈍くなるということで、今日はどうでもいいようなところで悩んでいました。
例えば、下のようなクラスを作ります。
使うときはこんな感じになります。
意図した通り、これで 1 が出力されます。しかし、
とすると下のようなエラーが出力されます。
error: no matching function for call to ‘Test::Test(int*)’
いろいろ試行錯誤してみると
のようにポインタを定数とすればちゃんとコンパイルできました。実際はもう少し複雑なクラスの中で発生した問題だったので、最初はなぜこのような動作になるのか全くわからず、コンパイラのバグじゃないのと疑う始末。で、上に書いたようなクラスを使って検証した結果、
とすれば正常にコンパイルすることができて、&data[0] として渡した場合、定数ではないポインタへの参照としては扱われないということを理解しました。先週はこれにずっと頭を悩ませていたわけで、理由がわかって何かスッキリしました。というより、もっと早く気付けと過去の自分に言いたい
最近になって思うのは、温度より湿度のほうが「暑苦しい」という感覚に影響しているということです。30 度を超えていても湿度の低い日は案外エアコンなしで大丈夫だったりしました。逆に 30 度以下でも湿度が高いときは耐えられないですね。だいたい 60% くらいがリミットでしょうか。
暑いと思考回路も鈍くなるということで、今日はどうでもいいようなところで悩んでいました。
例えば、下のようなクラスを作ります。
template< class T >
class Test
{
T* t_;
public:
Test( T& t ) : t_( &t ) {}
void print( size_t i )
{ std::cout << (*t_)[i] << std::endl; }
};
使うときはこんな感じになります。
int data[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, };
std::vector<int> vec( &data[0], &data[sizeof(data) / sizeof(data[0])] );
Test< std::vector<int> > test1( vec );
test1.print( 1 );
意図した通り、これで 1 が出力されます。しかし、
Test< int* > test2( &data[0] );
test2.print( 1 );
とすると下のようなエラーが出力されます。
error: no matching function for call to ‘Test
いろいろ試行錯誤してみると
Test< int*const > test2( &data[0] );
のようにポインタを定数とすればちゃんとコンパイルできました。実際はもう少し複雑なクラスの中で発生した問題だったので、最初はなぜこのような動作になるのか全くわからず、コンパイラのバグじゃないのと疑う始末。で、上に書いたようなクラスを使って検証した結果、
int* p = &data[0];
Test< int* > test2( p );
とすれば正常にコンパイルすることができて、&data[0] として渡した場合、定数ではないポインタへの参照としては扱われないということを理解しました。先週はこれにずっと頭を悩ませていたわけで、理由がわかって何かスッキリしました。というより、もっと早く気付けと過去の自分に言いたい
2015年07月12日
C++ メモランダム (template)
大相撲の名古屋場所が始まりました。いよいよ本格的な夏のスタートという気分です。
今日は全国的に真夏日ということで、名古屋も非常に暑い一日でした。熱射病や水の事故のニュースも流れていて、これから要注意ですね。台風の影響で大雨なんかにも気をつけたいところです。
-----
C++ の持つ機能の一つであるテンプレートの最も簡単な使い方として、任意の型に対して同じ処理を行うような場合にまとめて書いておくというものがあります。
template<class T> T sum( T t1, T t2 )
{ return( t1 + t2 ); }
型 T が和の演算子 ( + ) を使えるならどんな型でもこの関数が適用できます。特別バージョンを作りたければ
template<> SomeClass sum( SomeClass c1, SomeClass c2 )
{
SomeClass c = c1;
c.add( c2 );
return( c );
}
としておけば、引数が SomeClass の場合だけ下側が使われるようになります。
テンプレート関数は宣言だけしておくこともできます。例えば、sin の逆関数である asin は、float, double, long double 用に asinf, asin, asinl と関数名が分かれていますが、
template<class T> T Asin( T t );
template<> inline double Asin<double>( double t )
{ return( asin( t ) ); }
template<> inline long double Asin<long double>( long double t )
{ return( asinl( t ) ); }
template<> inline float Asin<float>( float t )
{ return( asinf( t ) ); }
としておけば、呼び出し側で型を変えても自動的に追随してくれます。特別バージョンだけ実装しておいても、他の型を利用しない限りはコンパイルできます。
ようやくテンプレートを上手に使いこなすための知識が身についてきて、様々なところで利用するようになってきました。やはり、問題になるのはエラーが出た時に内容が理解しづらいというところでしょうか。これも慣れるに従ってそれほど苦にはならなくなるものの、初めて見るようなエラーメッセージに対しては今でもしばらく悩むことがあります。 続きを読む
今日は全国的に真夏日ということで、名古屋も非常に暑い一日でした。熱射病や水の事故のニュースも流れていて、これから要注意ですね。台風の影響で大雨なんかにも気をつけたいところです。
-----
C++ の持つ機能の一つであるテンプレートの最も簡単な使い方として、任意の型に対して同じ処理を行うような場合にまとめて書いておくというものがあります。
template<class T> T sum( T t1, T t2 )
{ return( t1 + t2 ); }
型 T が和の演算子 ( + ) を使えるならどんな型でもこの関数が適用できます。特別バージョンを作りたければ
template<> SomeClass sum( SomeClass c1, SomeClass c2 )
{
SomeClass c = c1;
c.add( c2 );
return( c );
}
としておけば、引数が SomeClass の場合だけ下側が使われるようになります。
テンプレート関数は宣言だけしておくこともできます。例えば、sin の逆関数である asin は、float, double, long double 用に asinf, asin, asinl と関数名が分かれていますが、
template<class T> T Asin( T t );
template<> inline double Asin<double>( double t )
{ return( asin( t ) ); }
template<> inline long double Asin<long double>( long double t )
{ return( asinl( t ) ); }
template<> inline float Asin<float>( float t )
{ return( asinf( t ) ); }
としておけば、呼び出し側で型を変えても自動的に追随してくれます。特別バージョンだけ実装しておいても、他の型を利用しない限りはコンパイルできます。
ようやくテンプレートを上手に使いこなすための知識が身についてきて、様々なところで利用するようになってきました。やはり、問題になるのはエラーが出た時に内容が理解しづらいというところでしょうか。これも慣れるに従ってそれほど苦にはならなくなるものの、初めて見るようなエラーメッセージに対しては今でもしばらく悩むことがあります。 続きを読む
2015年06月28日
「間抜け」でソース管理
仕事でソース管理ソフトの git を利用することになり、個人のソース管理にも使ってみることにしました。
昔、CVS や Subversion で個人で作成したソースの管理をしてみましたが、途中ですぐに利用しなくなり、結局は「リネームしてバックアップ」というやり方で済ませていました。仕事では Visual Studio に付属している Visual Source Safe を使い、すでにサポート切れなのにもかかわらず、過去のプロジェクトでは未だに動いています。
最近、職場で git を使ってソース管理をするということになり、使い方を勉強中です。実は、前に一度だけ使ったことがあるものの、やはりすぐに利用しなくなりました。しかし、最近はソースの数も増えてゴチャゴチャとしてきたので、そろそろ整理することも含めてちゃんと使ってみようかと考えています。さて、今度はきちんと使いこなせるのでしょうか。
git は、Linux の生みの親である Linus Torvalds さんによって開発されました。Linus さん曰く "git" は自分にちなんだ名前として付けたそうです。その意味は「ばか」とか「間抜け」。なんとも自虐的なギャグです。
昔、CVS や Subversion で個人で作成したソースの管理をしてみましたが、途中ですぐに利用しなくなり、結局は「リネームしてバックアップ」というやり方で済ませていました。仕事では Visual Studio に付属している Visual Source Safe を使い、すでにサポート切れなのにもかかわらず、過去のプロジェクトでは未だに動いています。
最近、職場で git を使ってソース管理をするということになり、使い方を勉強中です。実は、前に一度だけ使ったことがあるものの、やはりすぐに利用しなくなりました。しかし、最近はソースの数も増えてゴチャゴチャとしてきたので、そろそろ整理することも含めてちゃんと使ってみようかと考えています。さて、今度はきちんと使いこなせるのでしょうか。
git は、Linux の生みの親である Linus Torvalds さんによって開発されました。Linus さん曰く "git" は自分にちなんだ名前として付けたそうです。その意味は「ばか」とか「間抜け」。なんとも自虐的なギャグです。





